Tools and Project Structure
In the following sections we will go over the steps for the implementation of a MLOps Proof-of-Concept pipeline using IBM Watson tools and services. A template repository with a complete MLOps cycle: versioning data, generating reports on pull requests and deploying the model on releases with DVC and CML using Github Actions and IBM Watson as well as instructions to run the project can be found here.
Note
We won't get into how to create predictive models or preprocessing data, since our main objective is to discuss MLOps and create a development cycle using those concepts.
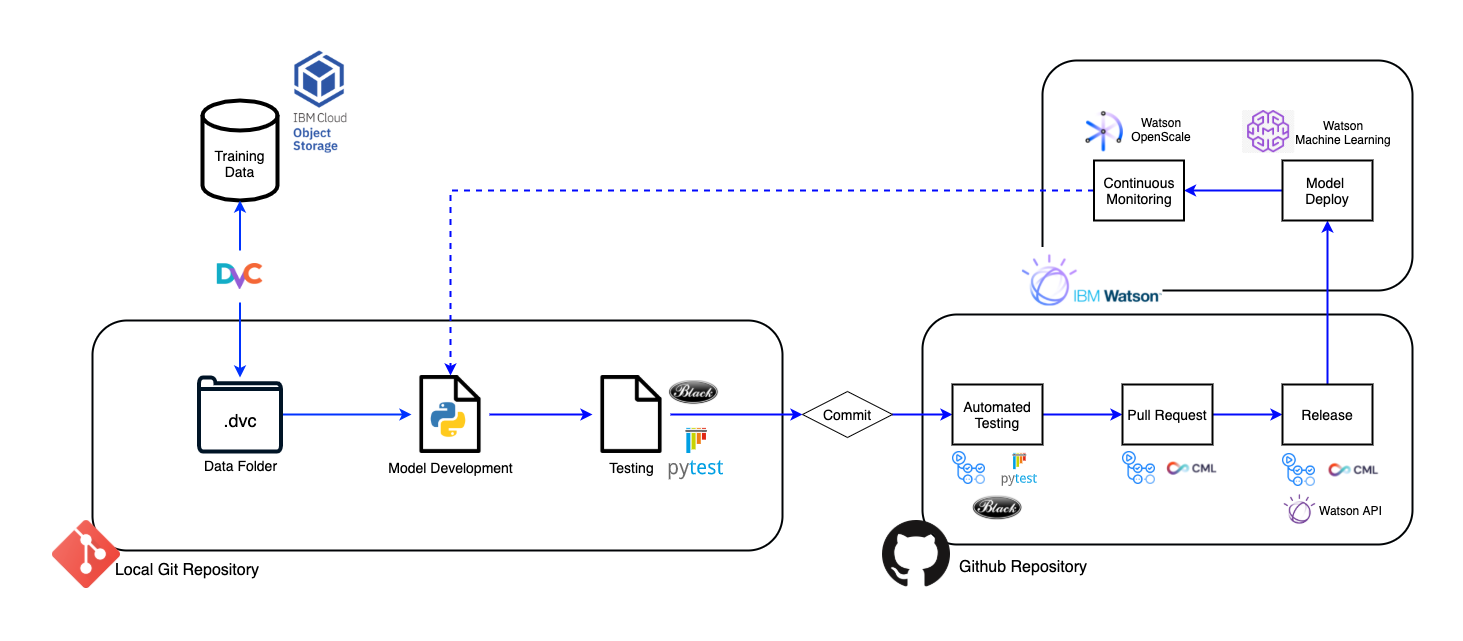
Project Tools
The main tools discussed in the guide are shown in the following table. As the guide is intended to be modular, a team can swap tools for others depending on the project necessities or preferences.
| Tools | Function | Developer |
|---|---|---|
| IBM Watson ML | Deploying model as API | IBM |
| IBM Watson OpenScale | Monitoring Model in production | IBM |
| DVC | Data and Model Versioning | Iterative |
| CML | Pipeline Automation | Iterative |
| Terraform | Setups IBM infrastructure with script | HashiCorp |
| Github | Code versioning | Github |
| Github Actions | CI/CD Automation | Github |
| Pytest | Python script testing | Pytest-dev |
| Pre-commit | Running tests on local commit | Pre-commit |
| Cookiecutter | Creating folder structure and files | Cookiecutter |
Folder Structure
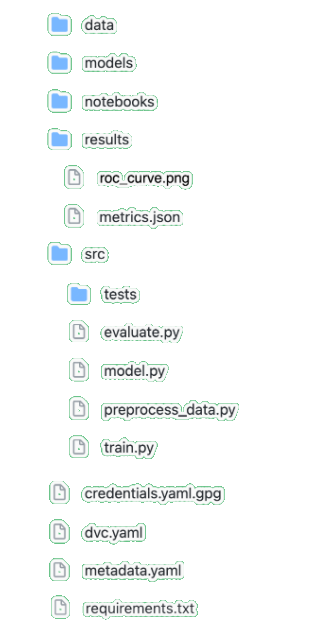
The above image is the project's folder structure, we'll talk about each specific part in further details trough out the guide.
-
data,modelsandresultscontain files which are being stored and versioned by DVC. -
notebookscontain Jupyter Notebooks used for the exploratory analysis, development of models, or data manipulation. -
srccontains scripts for training and evaluating the model as well as tests and scripts for pipelines and APIs.
This folder structure is going to be implemented in a blank project in Introduction/Starting a New Project with Cookiecutter
Requirements
The requirements file is a list of all of a project’s dependencies and the specific version of each dependency, including the dependencies needed by the dependencies. It can also be used to create a virtual environment. This is extremely important to avoid conflicts between Python libraries and also ensure the experiments can be reproduced in different machines.
Metadata File
To keep track of the model information we have a metadata.yaml file, this helps with CI/CD and pipeline automation. Such as updating or deploying the model without the need of user input.
author: guipleite
datetime_creted: 29/03/2021_13:46:23:802394723
model_type: scikit-learn_0.23
project_name: Rain_aus
project_version: v0.3
deployment_uid: e02e481d-4a56-470f-baa9-ae84a583c0a8
model_uid: f29e4cfc-3aab-438a-b703-fabc265f43a3
Using Jupyter Notebooks vs. Python Scripts
The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations, and narrative text. It is widely used in the fields of Data Science and Machine learning for its versatility in development and documentation of projects, however the usage of notebooks may cause some problems for our development cycle:
-
Versioning : Since notebooks source code are much more complex , we can't easily visualize the difference between versions using git. There are some tools that can help with that, however.
-
Reproducibility : A great feature of notebooks is being able to run cells in a non-sequential order, but this is a big problem if we want to reproduce the code, since it's hard to know in what order or which cells where executed, this is especially bad if we want to automate pipeline.
-
Standardized In/Out : By using scripts we can create pipelines with standardized entries and exits, therefore, we can create universal pipelines since no matter the model what it will receive and return will be in the same format.
-
Access to Functions : In the
model.pyscript, we define thetrainandevaluatefunction, where the model is declared and trained and the metrics for the evaluation are defined. These functions can be called by other scripts such astrain.pyandevaluate.pyso we can create pipelines to train the model on a remote instance or evaluate an already trained model file in a consistent form.def train(data, params): ... return pipeline, logs def evaluate(data, pipeline, OUTPUT_PATH): ... return results
In our project we choose to use scripts instead of Jupyter Notebooks for the reasons cited above, however notebooks could still be used as a form of experimentation of models or processes and the script as a more 'definitive' form.