What is DVC?
In the MLOps Concepts section we were able to show how versioning data, models, and pipelines are so important in an ML project. In this section, we will cover DVC and how you can set up this tool to version your data, models and automatize pipelines.
DVC, which goes by Data Version Control, is essentially an experiment management tool for ML projects. DVC software is built upon Git and its main goal is to codify data, models and pipelines through the command line.
This is all possible because DVC replaces large files (such as datasets and ML models) with small metafiles that point to the original data. By doing that, it's possible to keep these metafiles along with the source code of the project in a repository while large files are kept in at a remote data storage.
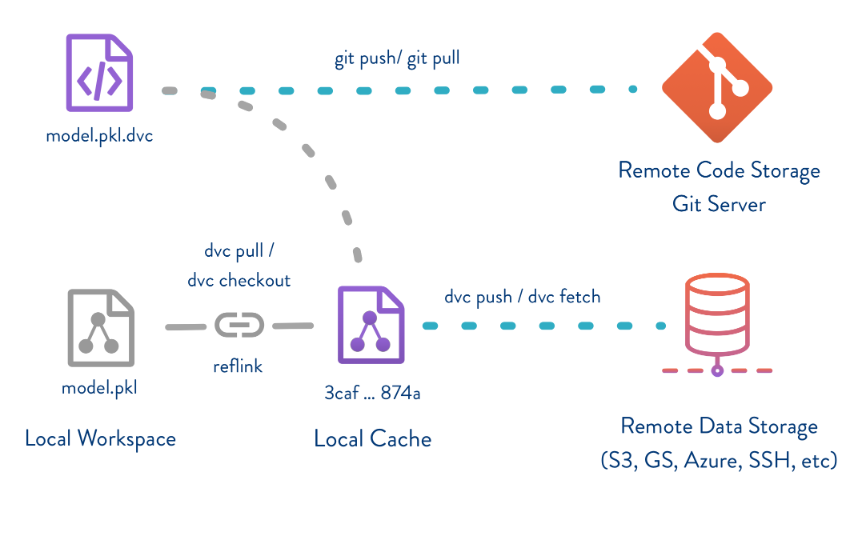
DVC workflow from https://dvc.org
Since DVC works on top of Git, its syntax and workflow are also similar so that you're able to treat data and model versioning just as you do with code. Although DVC can work stand-alone, it's highly recommended to work alongside Git.
DVC can also manage the project's pipelines to make experiments reproducible for all members. These pipelines are lightweight and are created using dependency graphs.
It's important to note that DVC is free, open-source and platform agnostic, so it runs with a diverse option of OS, programming languages and ML libraries.
Install
DVC can be installed as a Python Library with pip package manager:
$ pip install dvc
Depending on which remote storage interface you're using, it's important to install optional dependencies(s3, azure, gdrive, gs, oss, ssh or all). In this project we are using S3 interface to connect with IBM Cloud Object Storage.
$ pip install "dvc[s3]"
It's also possible to install DVC using conda:
$ conda install -c conda-forge mamba
$ mamba install -c conda-forge dvc
$ mamba install -c conda-forge dvc-s3
Project Setup
Initialization
After installing DVC, you can go to your project's folder and initialize both Git and DVC:
$ git init
$ dvc init
If you run git status, you can check DVC's initial config files that were created.
Remote Storage
Finally, we are going to setup our remote storage to keep our datasets and models.
With dvc remote add you can point to your remote storage.
$ dvc remote add -d remote-storage s3://bucket_namme/folder/
DVC uses by default AWS CLI to authenticate. IBM Cloud Object Storage works with S3 interface and also AWS, the only additional step here is to configure the IBM endpoint and configure the credentials.
$ dvc remote modify remote-storage endpointurl \
https://s3.us-south.cloud-object-storage.appdomain.cloud
To configure the credentials you can use default ~/.aws/credentials file and just add a new profile, or point to a new credential path:
Run:
$ dvc remote modify myremote profile myprofile
~/.aws/credentials
[default]
aws_access_key_id = ************
aws_secret_access_key = ************
[myprofile]
aws_access_key_id = ************
aws_secret_access_key = ************
or
$ dvc remote modify credentialpath /path/to/creds
If you have any problems trying to configure your remote storage, go check DVC docs for remote command